
Five Things: June 7, 2026
Executive order happened, Claude writes Claude, letter(s) on AIxBiosecurity, risk of AI bioweapons

Five things that happened/were publicized this past week in the worlds of biosecurity and AI/tech:
The White House is back on board, for real this time
Anthropic employees talk about how Claude helps create Claude
Letter(s) pushing for DNA synthesis screening
SecureBio on AI-Bio capabilities
A proposal for AIxBio pre-development risk assessment
[drafted with some help from Claude]
1. White House action is back for real!
There’s been a lot of flip-flopping over the past week at the White House on whether or not there would be an executive order on AI regulation, but apparently, things have gotten to a point where doing nothing was not an option. Well, something has finally happened! On June 2 Trump signed a version of the executive order (EO) that was being floated around for two months, “Promoting Advanced Artificial Intelligence Innovation and Security.”
What’s in the EO? Well, it’s all optional, but if they want to, frontier AI developers can give government agencies 30 days to “review” new “covered frontier models” before public release. This review is voluntary, classified, and squarely cyber-focused; other catastrophic risks (including, conspicuously, bio) are out of scope. The NSA gets a central role in building the benchmarks, but it seems like the main review should be done with CISA. I’m not the right guy to give more commentary on this, but there is certainly a lot out there.
More recently, on June 5, the White House issued NSPM-11, directing rapid AI adoption across the defense and intelligence enterprise around four pillars (Adoption, Adaptation, Assurance, Accountability), with civil-liberties guardrails prohibiting AI use for censorship or unlawful surveillance and a 90-day deadline to update DoD Directive 3000.09 on autonomy in weapons. The memo helpfully informs us that “the United States possesses the most effective and moral military in the history of the world.” I have no idea what goes on inside, but this sounds to me a little bit like it might have been part of a compromise to get the anti-safety people on board; if the frontier models are going to be holding back their model releases for the government to review, then at least the army should be allowed to get their autonomous killer robots.
2. RSP vs RSI
Anthropic published a wild piece, “When AI Builds Itself”, describing the dizzying increase in AI research that is just beginning now with Claude able to help build its own future iterations, complete with ‘testimonies’ from Anthropic employees about how they are using Claude. The headline is that they claim over 80% of production code that they ship is now authored by Claude, but a lot of other numbers and details that made reading the whole piece give me a sense of vertigo. The essay ends off with a discussion of what this means, will it scale/continue, and only kind of hints to the obvious implications for catastrophic outcomes (but the details are almost unnecessary at this point). It happens to be that I noticed yet another arXiv paper posted this week arguing against trying to automate alignment research: optimization pressure concentrates AI mistakes exactly where human reviewers are least able to catch them, and shared training makes AI reviewers’ errors correlated rather than diverse.
For years people in AI have been talking about RSI — recursive self-improvement — as the scariest part of the transition to the AI future. AI-2027 authors Daniel Kokotajlo and Scott Alexander, for example, liked to say that they are really describing something that should take about a century, but that RSI means that a century of technological advance happens in a just a few years thanks to the math of exponential growth in capabilities.
Anthropic bills itself as the responsible company here, and all its efforts on this front (including the publication of documents such as these) should be commended, but... admitting that you are on a dangerous path is only slightly less responsible than doing the same thing while not admitting it? How does the RSI fit with Anthropic’s RSP, their Responsible Scaling Policy?
3. Make DNA screening mandatory
The CEOs of the four biggest AI labs — Sam Altman (OpenAI), Dario Amodei (Anthropic), Demis Hassabis (Google DeepMind), and Mustafa Suleyman (Microsoft AI) — signed a letter to Congress calling for laws that would require sellers of synthetic DNA and RNA to screen both customer orders and customer identities. The letter was organized by the Institute for Progress and the Foundation for American Innovation, which WIRED describes as “a rare source of agreement among libertarians, progressives, researchers and rival executives.” A similar group in Australia, Australians for AI Safety open letter (141 individuals, 12 organizations) wants mandatory screening down under. And as Zvi put it, this is a real easy one; everyone should be on board.
The core worry, in the letter’s words:
there is a real possibility that the knowledge barriers which have historically prevented bad actors from obtaining biological weapons will meaningfully erode.
In other words, AI models will allow people to order everything they need to make a biological weapon in their basement. There’s still a huge question as to how many people would be successful at doing this, even with the help of a friendly LLM, but there is no reason to make it easy for people to order dangerous DNA sequences from gene synthesis providers. Luckily the major companies in the US do this screening already, but the work could use boosting (through laws and money). Making it mandatory seems like a very obviously good idea. Dean Ball in the Wall Street Journal (Foundation for American Innovation) put it this way: “If you’re synthesizing the stuff that yields biological life and viruses, we’re asking you to screen to see whether it is dangerous in some way. That seems like a reasonable thing for society to insist upon.”
The slightly awkward backdrop is that Trump revoked the Biden-era gene-synthesis screening framework and hasn’t published a replacement, which is why screening is voluntary for now — the International Gene Synthesis Consortium screens, but plenty of providers don’t. Together with the letter, the Institute for Progress laid out the policy detail in a companion brief, and cites a lot of the research that I’ve been following/citing in this here newsletter over the past months.
OpenAI, conveniently, announced its Rosalind Biodefense trusted-access program the same day (see “In other news”), so the letter doubles as a coordinated PR moment. As cynical as I’d like to be about that, I think it is correct that we’ll need AI systems for screening potentially harmful DNA sequences. So yes, the AI companies are also selling the “antidote” to their own “poison.” That is somewhat inevitable in this case, but we should also remember that (1) in theory, we don’t need to “buy” either of them, (2) there are other options besides OpenAI’s models (ESMFold2, for example, and similar biological AI models from nonprofits have a good chance of being better candidates here).
4. Understanding the risks of AI biology: LLMs
How do we actually know whether an AI model can do dangerous biology, and what/when can/s we do anything about it? Things #4 and #5 are two great pieces looking at how we can figure out whether or not a biological model poses a risk of biological misuse — I’m splitting them into two because one is about LLMs (such as ChatGPT, Claude, etc) and the other focuses on biological tools (ESMFold, Evo2, etc).
First, SecureBio’s Jasper Götting has a really great essay covering evals (such as their Virology Capabilities Test and similar benchmarks that they work on) as the pragmatic middle tier of a biorisk “evidence hierarchy” — more rigorous than hand-waving from first principles, but vastly cheaper than a properly-powered wet-lab uplift study (tens to hundreds of thousands of dollars versus millions). A multiple-choice biology benchmark “measures something, but what it’s measuring isn’t obviously” the thing we actually care about — whether a person could build a working pathogen. He notes that only the Active Site RCT currently clears the bar of “a sufficiently large study,” so for now evals are best understood as a repeatable monitoring tool between the expensive studies, not a verdict. Götting’s essay is a really nice and accessible overview of why the field looks like it does, the pros and cons of various evaluation regimes and how he thinks especially about the list of known limitations to computational methods of capabilities testing.
5. Understanding the risks of AI biology: Biological AI tools
So much for general-purpose models AI models (really, chatbots) and how SecureBio tests them to see what they can do. But there is another category if AI models that are specifically built to do biology, which are systems trained on protein, genomic, or structural data rather than internet text.
A new Frontiers in Microbiology paper from the Johns Hopkins Center for Health Security argues that so far, almost all of our risk effort for understanding these tools happens too late after a model is trained (often, even after it is already public). The best work on this front (in my opinion) has been the Global Risk Index for AI-Enabled Biological Tools, a detailed risk-scoring index from RAND and the UK’s Centre for Long-Term Resilience, but this required going to subject matter experts to ask them to score risk potential of tools that were already published.
What we should be considering before anything though, is whether or not these models are worth building in the first place, and so the authors argue that developers should conduct “risk–benefit review” (RBR) at the funding/conception stage. The clever part of the argument is why BAIMs suit upstream review where chatbots don’t: a general-purpose model’s dangerous capabilities (bioweapon ideation, say) emerge unintentionally, but a BAIM is built on purpose to do one specific thing, so you generally know at conception whether you’re training something to, e.g., predict the viral mutations that escape our immune systems.
An Epoch AI survey from earlier this year showed that, of more than 1,100 biological AI models, fewer than 1.5% have any safeguards against misuse. It would be nice if we actually had a better idea of what these models are even capable of, what dangers might be involved in their use or publication, and what kinds of safeguards are available that would allow for beneficial biological discovery without allowing people to invent harmful new pathogens.
In other news...
On AI doing (or not doing) things:
TechCrunch reports (following the Financial Times) that Anthropic has embedded roughly six engineers at the NSA to help the agency stand up Mythos, its frontier cybersecurity model, for use in cyber operations.
Stanford law professors preferred AI answers to peer answers in blinded first-year Contracts tutoring: a 75% win rate across 2,918 comparisons, with AI flagged as pedagogically harmful far less often than humans (3.5% vs. 12%). Claude Opus 4.7 topped the model ranking, but every model outranked the human instructors. Woah!
Rest of World catalogs five governments embarrassed by AI hallucinations: South Africa withdrew an AI policy with fabricated citations after 17 days; Deloitte refunded $290,000 for an Australian report full of fake references; the MAHA health report contained literal “oaicite” tags.
The Economist notes 44% of US state legislative staff used AI in 2025 (up from 20%). One Vermont legislator uses it to fact-check lobbyists live in committee: “I’ve actually caught lobbyists in lies.” A Kansas rep is less sold: “Your constituents aren’t electing Claude or ChatGPT.”
John Burn-Murdoch has the FT’s chart(s) of the week, built on a recent MIT study the actual gains from AI’s coding ability shrink as you move down the pipeline. I think this is a good chart to put together with all the SaaS-pocalypse discussion:
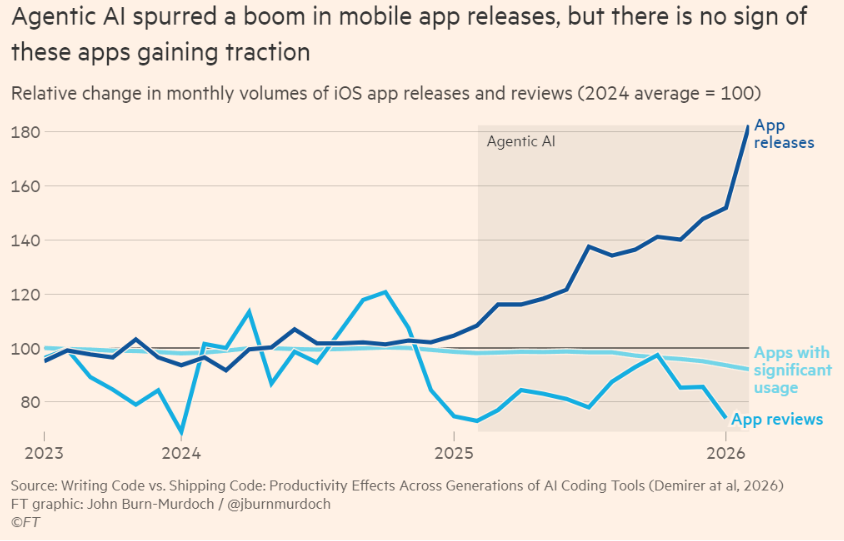
AI safety and alignment:
MIT FutureTech’s 272-expert Delphi study finds 18 of 24 AI risk domains carry ≥10% probability of catastrophic outcomes within five years on current trajectories. I’m already a boiled frog here in that this doesn’t surprise me at all, but how is this not a bigger deal in the public consciousness?!?!
A Google DeepMind position paper argues a “solipsistic” superintelligence, which is trained to treat the world as a fixed source of feedback, won’t be cooperative, because deploying it changes the very world it modeled.
A Mount Sinai clinical-sycophancy study found frontier models abandon correct medical advice under social pressure, and “persona features” strikes again: that the “medical student” persona triggered sycophancy ten times more often than the “senior physician” one (19.3% vs. 1.8%).
Jack Clark gave a good interview conversation with Rory Stewart and Matt Clifford, discussing the crazy situation of Anthropic trying to be a “responsible” company; bioweapons makes several appearances.
AI and society:
Trump told reporters the US government may take equity stakes in AI companies like OpenAI so “American people can benefit” — with Anthropic, OpenAI, and xAI summoned to the White House to discuss it. Similarly, (yes, I said similarly), Bernie Sanders had floated a one-off 50% tax on AI labs to seed a sovereign wealth fund.
Two latest takes on whether AI is a ‘bubble’, now with the news of Anthropic’s impending IPO: Alberto Romero argues the industry is “running out of time” and rushing to IPO to offload risk onto public markets; Azeem Azhar and Nathan Warren counter that it’s “still no bubble” on five centuries of indicators, with sector revenue nearly doubling to $25B in Q1. I think both are possible in a world where the real revenue is anticipatory and uncertain (which it is!).
Fan-of-the-newsletter Stephen D. Turner proposes an “AI Dry July,” a month off the chatbots to fight skill erosion/cognitive offloading that inevitably comes from relying on these tools too much. I think one month per year might be too hard, but what about one day a week (or every other week) of working without AI use?
AI for biology:
Anton Nekrutenko shows a “recipe–implementer” split for agentic lab analysis: an expensive frontier model writes the analysis plan once, then a free local open-weight model executes it many times.
On the question of DNA synthesis screening, GCBR notes that SecureBio’s CASPER metagenomic database now holds 1.3 trillion reads (with AI cutting the human review load by ~80%) and that IBBIS’s DNA-screening consortium just reached Category A liaison status with ISO, so the infrastructure for Thing #3 above is pretty much there.
Rowan on OpenFold3.
Jesse Johnson’s argument that MCP is the new SaaS for biopharma software integration, which is 100% how I think about this too.
Biosecurity/bioethics generally:
The DRC/Uganda Ebola outbreak is, as expected, getting worse: 321 confirmed DRC cases (48 deaths) as of June 1. Obviously this is sad, and I don’t want to make light of people dying from a terrible disease, but the epidemiologists reassure us that this Bundibugyo-strain outbreak isn’t a pandemic threat: “A disease that mostly spreads from people who are visibly, severely ill is a disease you can, in principle, contain.” CEPI and GAVI are advancing vaccine work. The Global Shield briefing tallies 746+ suspected cases across both countries.
Among other points, the latest Pandora Report notes Syria recovered 54 M4000 aerial bombs and 25 Volcano rockets the Assad regime hid for over a decade, and that New World screwworm has been (preliminarily) detected in South Texas with a potential $1.8B hit to the state.
Science writer Carl Zimmer reports that a Columbia team managed to edit early human embryos with far less collateral damage than usually seen by using CRISPR. This is the cleaner instrument everyone knew was coming, applied to the one substrate everyone agreed to leave alone after the 2018 He Jiankui scandal (he served three years in prison for editing the first gene-edited babies).